Introduction
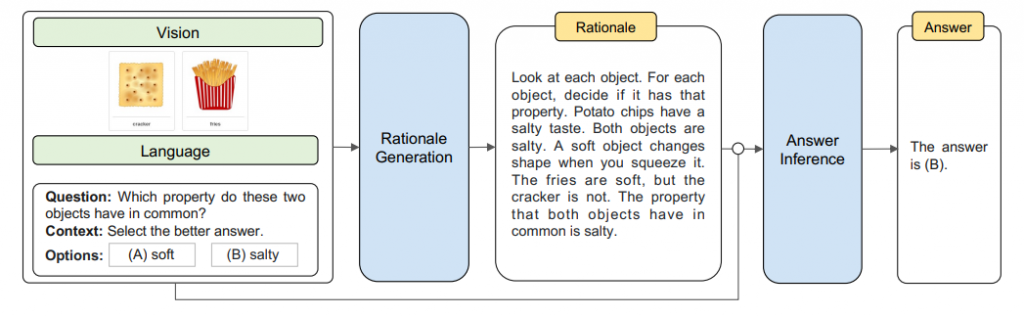
Retrieval-Augmented Generation (RAG) is a cutting-edge methodology that combines retrieval methods to address the static limitations of large language models (LLMs). This integration allows models to dynamically incorporate up-to-date external information, enhancing their accuracy and reliability by grounding responses in real-world data. This blog talks about a more advanced RAG pipeline called The RAG paradigm, which is structured into four main phases: pre-retrieval, retrieval, post-retrieval, and generation, each contributing uniquely to the overall effectiveness of the pipeline.
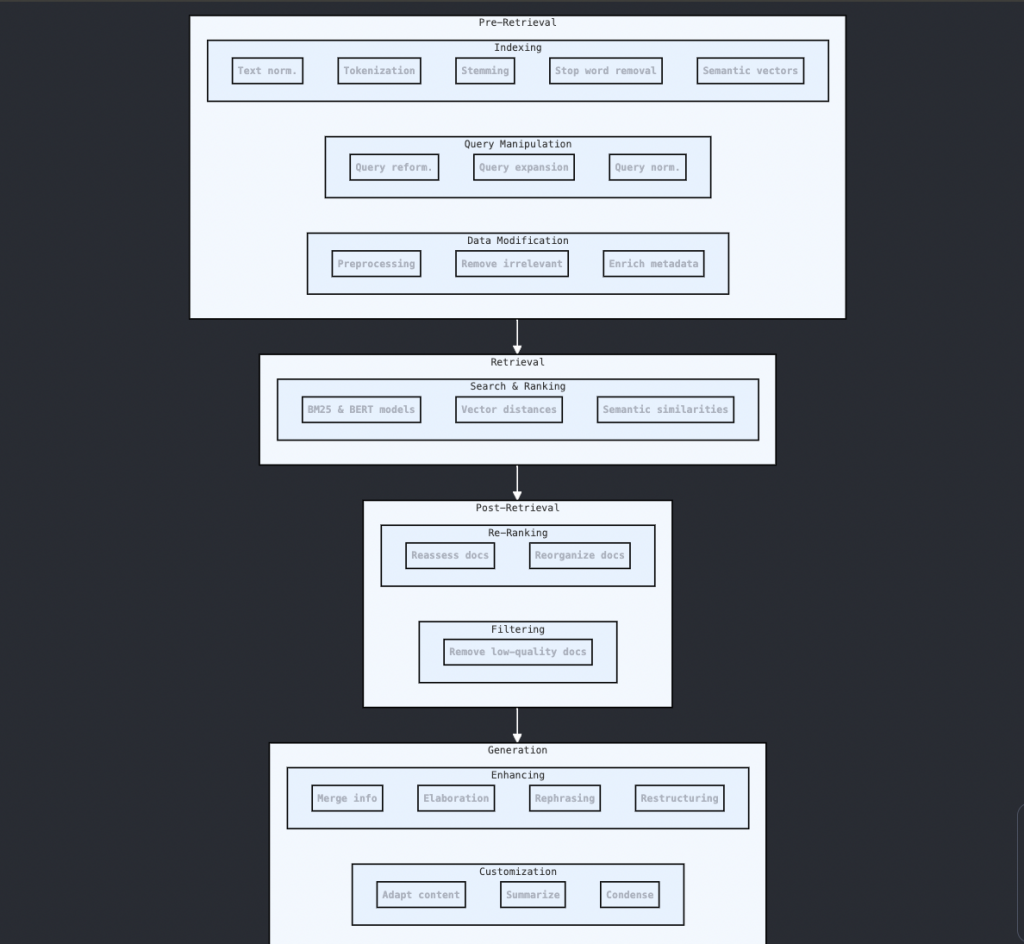
Pre-Retrieval
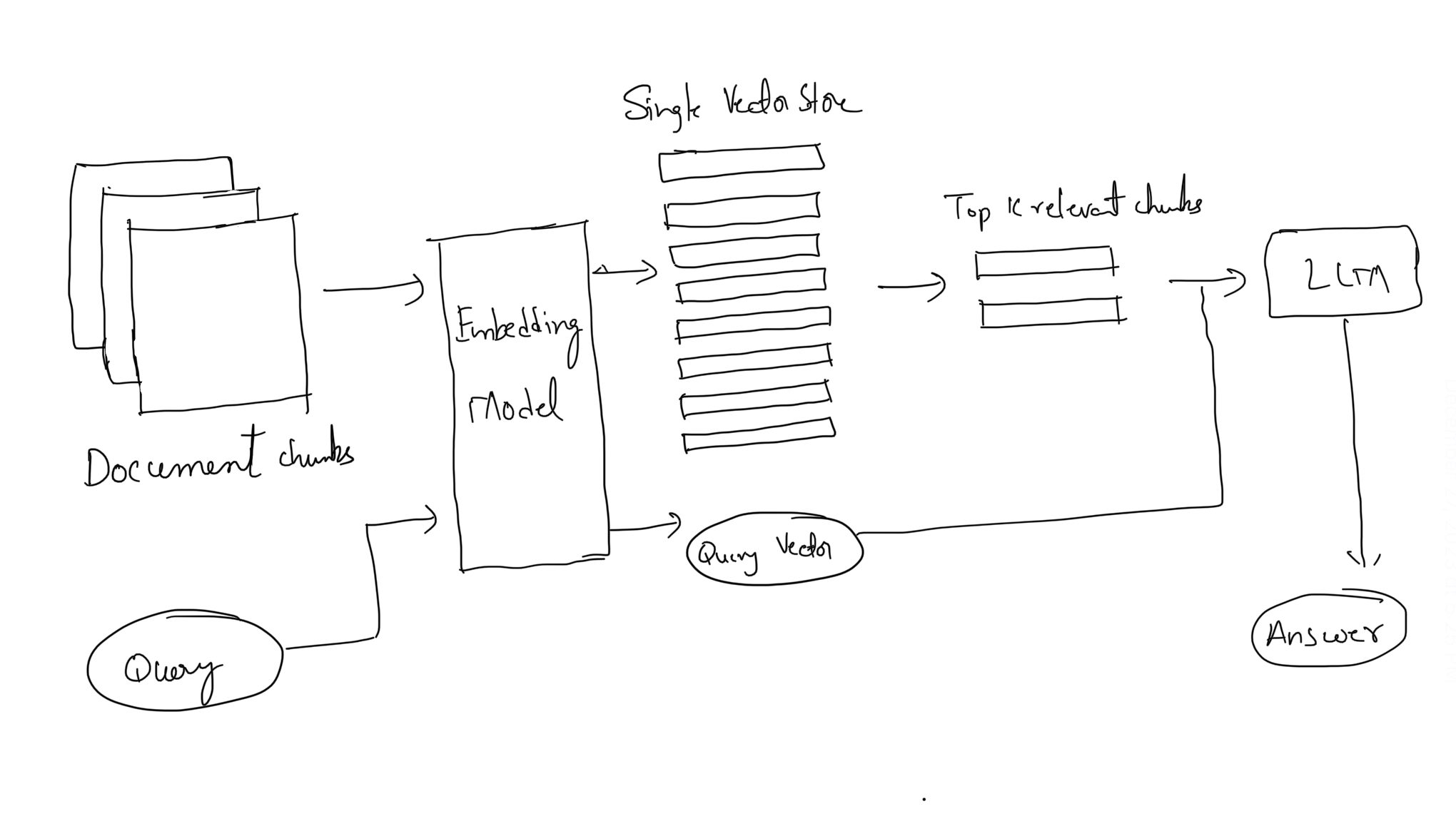
Indexing: The pre-retrieval phase lays the groundwork for efficient information retrieval. It begins with indexing, where data is prepared for quick and accurate access. This involves text normalization (tokenization, stemming, stop word removal) and the organization of text into sentences or paragraphs. Advanced indexing techniques use pre-trained language models (LMs) to generate semantic vector representations of texts, stored for rapid retrieval.
Query Manipulation: This involves refining user queries to better align with the indexed data. Techniques include query reformulation (rewriting queries for clarity), query expansion (adding synonyms or related terms), and query normalization (standardizing spelling and terminology).
Data Modification: This step enhances retrieval efficiency by preprocessing data to remove irrelevant or redundant information and enrich it with metadata, improving the relevance and diversity of retrieved content.
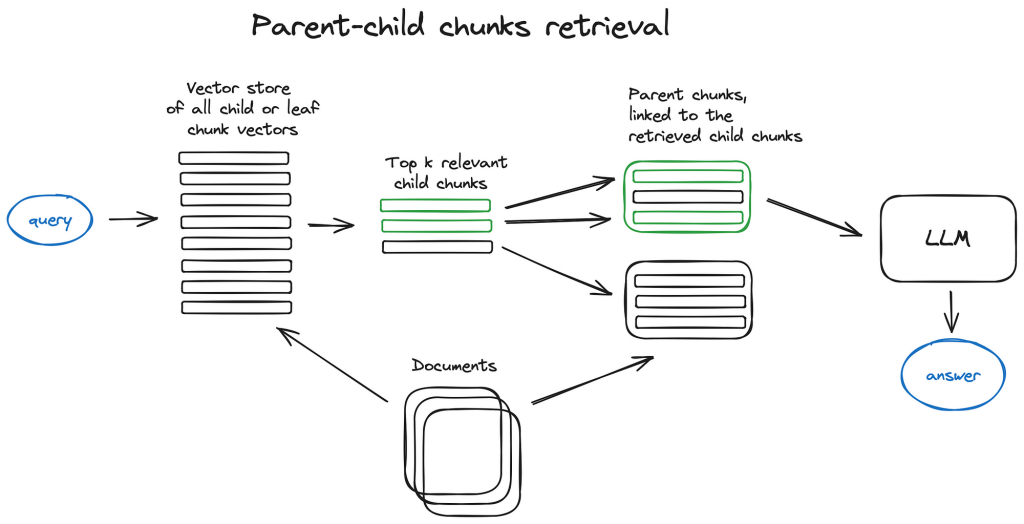
Retrieval
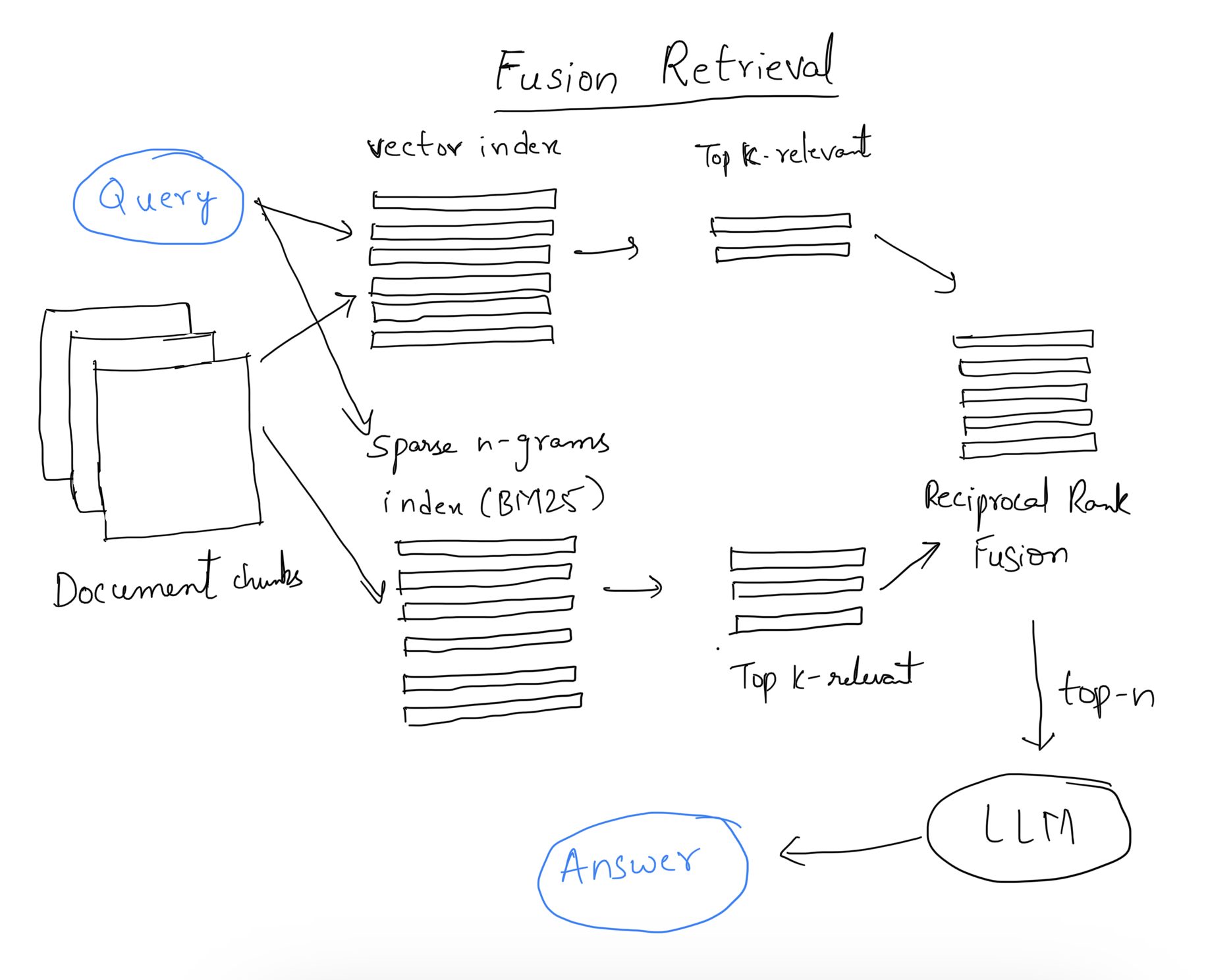
Search & Ranking: The retrieval stage combines search and ranking to select and prioritize documents from the dataset. Traditional retrieval methods like BM25 are enhanced with pre-trained LMs like BERT, which capture the semantic essence of queries more effectively. These models measure vector distances between documents and queries, refining document ranking through semantic similarities, thus improving search accuracy.
Post-Retrieval
Re-Ranking: Post-retrieval involves refining initially retrieved documents to improve generation quality. Re-ranking reassesses and reorganizes documents based on additional metrics and external knowledge sources, highlighting the most relevant documents.
Filtering: This step removes documents that do not meet quality or relevance standards, often using relevance evaluations like sending entities to filter documents or create summaries of the documents and use only relevant to the user query, etc to ensure only the most pertinent documents are used for generation.
Generation
Enhancing: The generation phase merges retrieved information with the user’s query to create a coherent and relevant response. This involves elaboration, rephrasing, and restructuring to improve the clarity, coherence, and stylistic appeal of the output.
Customization: Optional but valuable, customization adapts the content to meet specific user preferences or contextual needs. This includes summarizing, condensing information, and aligning the output with the target audience or presentation format.
Advanced RAG Techniques
Multi-Hop Retrieval: Unlike single-hop retrieval, which retrieves information in one step, multi-hop retrieval iterates between retrieval and generation. This iterative process refines the accuracy and relevance of retrieved information, significantly improving the quality of the final output.
Modular RAG Platforms: Platforms like LangChain and LlamaIndex modularize the RAG approach, enhancing adaptability and expanding its range of applications. These platforms maintain the fundamental RAG workflow while employing diverse methodologies to tackle different aspects of RAG, such as multiple search iterations and iterative generation.
Innovative Retrieval Methods: Recent advancements include Differentiable Search Indices, which integrate retrieval within a Transformer model, and Generative Models for Search, which generate document titles and evidence sentences for fact-verification tasks. These methods offer superior performance and efficiency.
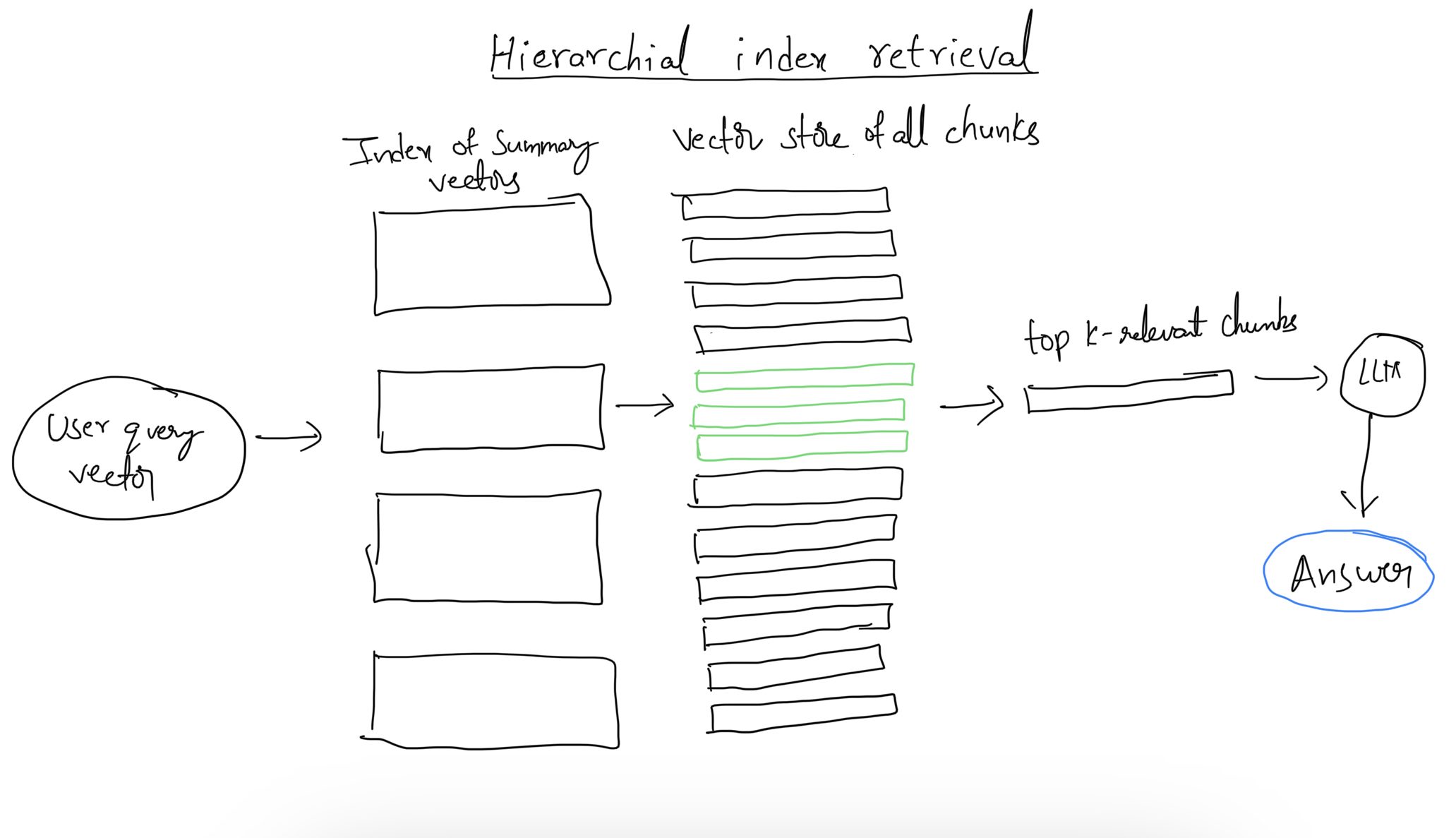
Enhanced Indexing: Techniques like FAISS (Facebook AI Similarity Search) and hierarchical navigable small-world (HNSW) graphs improve retrieval speed and accuracy. Innovations like MEMWALKER create a memory tree from input text, efficiently managing large volumes of information.
Sophisticated Query Manipulation: Methods such as Step-Back and PROMPTAGATOR abstract high-level concepts and utilize LLMs for prompt-based query generation. These strategies better align queries with retrieval systems, enhancing retrieval relevance and insight.
Evaluation and Future Directions
Evaluation Frameworks: Evaluating RAG systems involves assessing the quality of the generated text, the relevance of retrieved documents, and resilience to misinformation. Metrics like Exact Match (EM) and F1 scores are standard, but new frameworks also consider noise robustness, negative prompting, and counterfactual robustness.
Multimodal RAG: Combining textual and visual information for language generation is a growing area. Models like MuRAG and Re-Imagen enhance visual question answering and text-to-image generation, showcasing the potential of multimodal RAG.
Improving Retrieval Quality: Future research aims to enhance retrieval methods, focusing on integrating retrieval with language generation models to handle vast amounts of data effectively and reliably.
Conclusion
The RAG paradigm offers a robust framework for integrating retrieval methods with LLMs, significantly improving their accuracy and reliability. By structuring the workflow into pre-retrieval, retrieval, post-retrieval, and generation phases, RAG provides a comprehensive approach to leveraging real-world data. As advancements continue, particularly in multi-hop retrieval and multimodal RAG, the potential applications and adaptability of RAG are set to expand, driving further innovations in the field of natural language processing.