




Prompt Engineering Techniques Part – 1
Prompt Engineering Techniques Part – 1
As Language Models (LLMs) continue to become more sophisticated, prompt engineering techniques have become increasingly essential to make the most of their capabilities. Prompt engineering involves crafting the right input prompts to prompt the LLMs to generate the desired outputs. In this article, we’ll explore four prompt engineering techniques:
- Zero-shot or few-shot prompts
- Chain of thought prompting
- Self-consistency
- Knowledge generation prompts
Zero-shot or few-shot prompts:
Zero-shot prompting involves presenting a task or question to the model without providing prior examples or context. For instance, we could use zero-shot prompting to ask a language model to analyze the sentiment of a given tweet and classify it as positive, negative, or neutral.
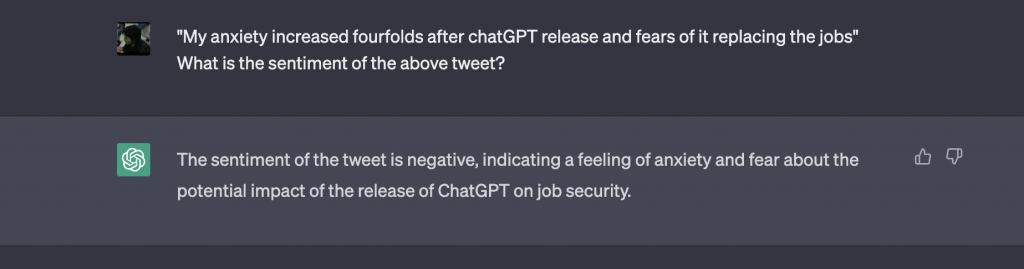
On the other hand, few-shot prompting involves providing a language model with a task or question along with a few examples of the desired output. This approach helps steer the model toward generating responses that are more relevant to the task at hand. For example, we could use a few shot prompting to give us the sentiment response of the tweet in a format that we desire as shown in the example below:

Chain of Thought (CoT):
Chain of Thought (CoT) Prompting is a technique used to enhance performance on complex reasoning tasks and generate more context-aware responses. This method was proposed by Google in 2022. The authors explain that this reasoning ability can be developed in language models via a simple process of providing a few chains of thought demonstrations, known as CoT prompting. With CoT prompting, the model is instructed to produce a few reasoning steps before generating the final answer.
For example, we can use CoT prompting to solve a customer churn problem. Consider the following scenario:

Using CoT prompting, the language model is prompted to generate a few intermediate reasoning steps to arrive at the final answer. This may include calculating the total number of customers at the end of the month, subtracting the number of customers lost due to churn, and dividing the result by the starting number of customers. By prompting the model to generate a chain of thought, we can ensure that the model arrives at the correct answer while also gaining insight into the reasoning process used by the model.
Self-Consistency:
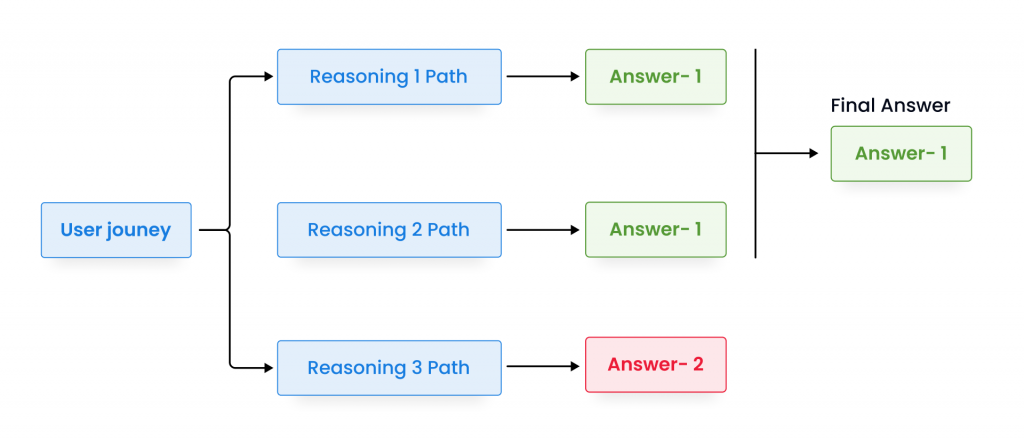
Self-consistency is a decoding strategy that aims to improve the chain of thought prompting more complex reasoning problems. The traditional approach of using a single reasoning path may not always yield the most comprehensive or accurate results, as complex reasoning problems often have multiple valid solutions that can be arrived at through different paths. To overcome this limitation, self-consistency involves sampling from a diverse set of reasoning paths and selecting the most consistent answer.
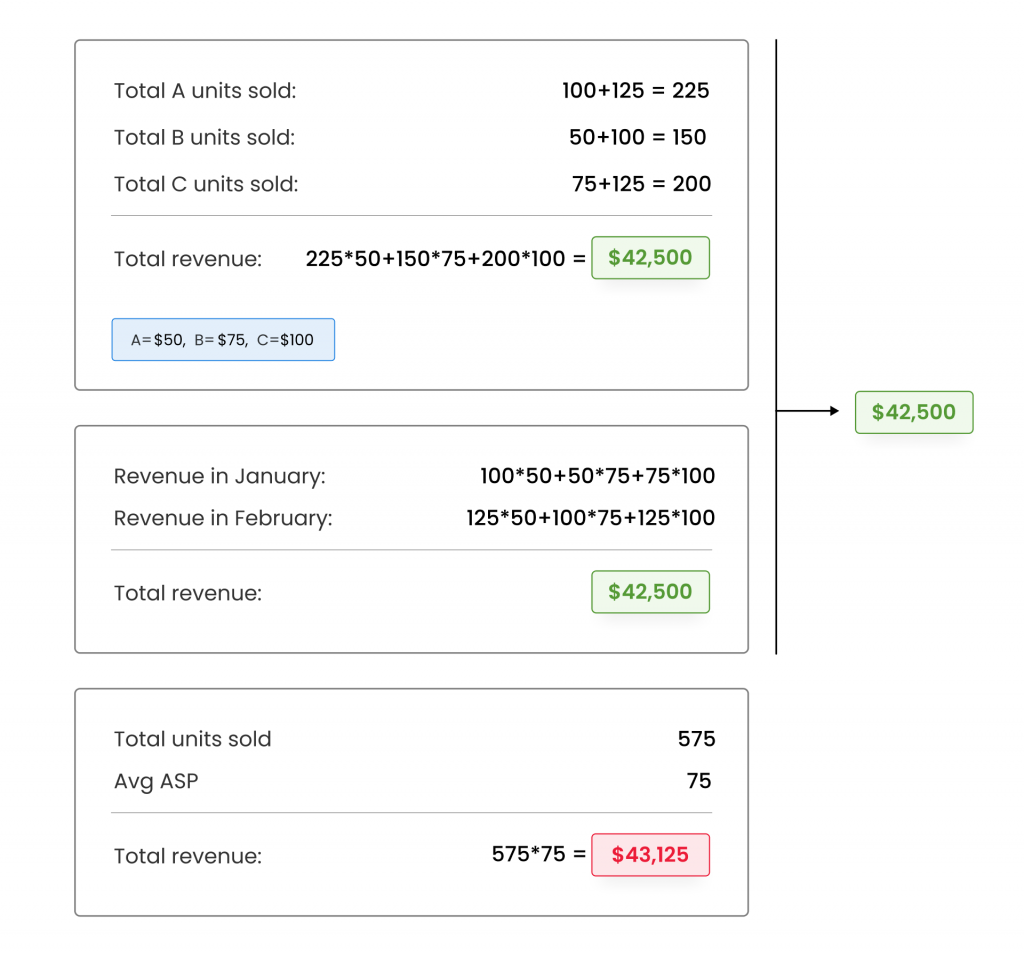
User: Q: A company sells three types of products: Product A, Product B, and Product C. The sales data for the month of January is as follows: Product A – 100 units, Product B – 50 units, and Product C – 75 units. The sales data for the month of February is as follows: Product A – 125 units, Product B – 100 units, and Product C – 125 units. If the average price of Product A is $50, Product B is $75, and Product C is $100, what is the total revenue earned by the company for the two months?
To solve this problem using self-consistency prompting, the language model first generates a diverse set of reasoning paths, considering various factors such as the sales data, average price, and time period. The model then selects the most consistent answer by marginalizing out the sampled reasoning paths.
Knowledge generating:
Generated knowledge prompting is a technique that utilizes additional knowledge provided as part of the context to improve the performance of complex tasks such as commonsense reasoning. It involves using a language model to generate question-related knowledge statements, which are then used in a second language model to make predictions. The highest-confidence prediction is selected as the final output, which helps to improve the accuracy of the model.
This technique offers a simple and effective way to incorporate external knowledge into pre-trained sequence models, without requiring task-specific supervision or access to a structured knowledge base.
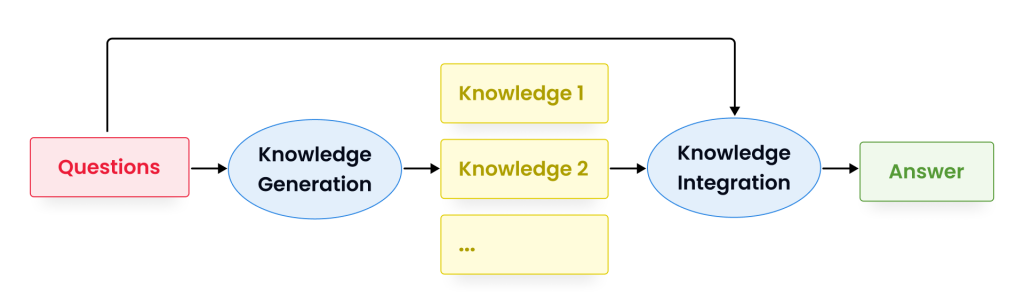
Consider the following task:
Question: “What will happen if you put a metal spoon in a microwave oven?”
Answer choices:
A) The spoon will melt
B) The microwave will explode
C) Nothing will happen
D) The spoon will get hot
To solve this problem using generated knowledge prompting, we could generate knowledge statements for metal and microwaves. For example:
- “Metals conduct electricity well”
- “Microwaves heat food by exciting water molecules”
We would then use a second language model to make predictions for each statement. Based on the highest-confidence prediction, we can choose the answer option that is most likely to be correct. In this case, the correct answer would be D) The spoon will get hot, based on the knowledge generated.
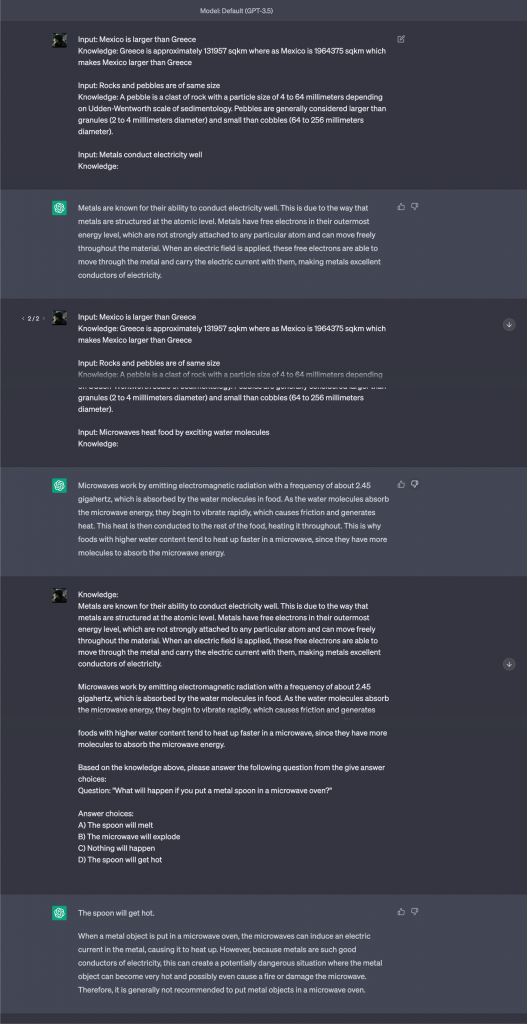
Please check the whole prompt sequence below:
Get ready to take your prompt engineering skills to the next level! In part-1 of “Advanced prompt engineering techniques,” we covered some fundamental techniques, but in part-2, we’ll explore even more advanced strategies. Don’t miss out on this opportunity to enhance your NLP expertise – read on to part-2 now!









