




The Ultimate Guide on Retrieval Strategies – RAG (part-4)

The Ultimate Guide on Retrieval Strategies – RAG (part-4)
Table of Contents
Overview:
Retrieval-augmented generation (RAG) has revolutionized how we interact with large datasets and corpus of information. At its core, the retrieval process in RAG is about sourcing relevant external data to enhance response generation. This external integration allows models to produce responses that are not just accurate and detailed, but also contextually richer, especially for queries needing specific or current knowledge.
In this guide, we’ll explore various retrieval methods, breaking down complex concepts into digestible parts, and ensuring you get the most out of RAG’s potential. Please note this is a continuation of the RAG article part 3
Retrieval Methods
1. Search Methods
1.1 Vector Store Flat Index
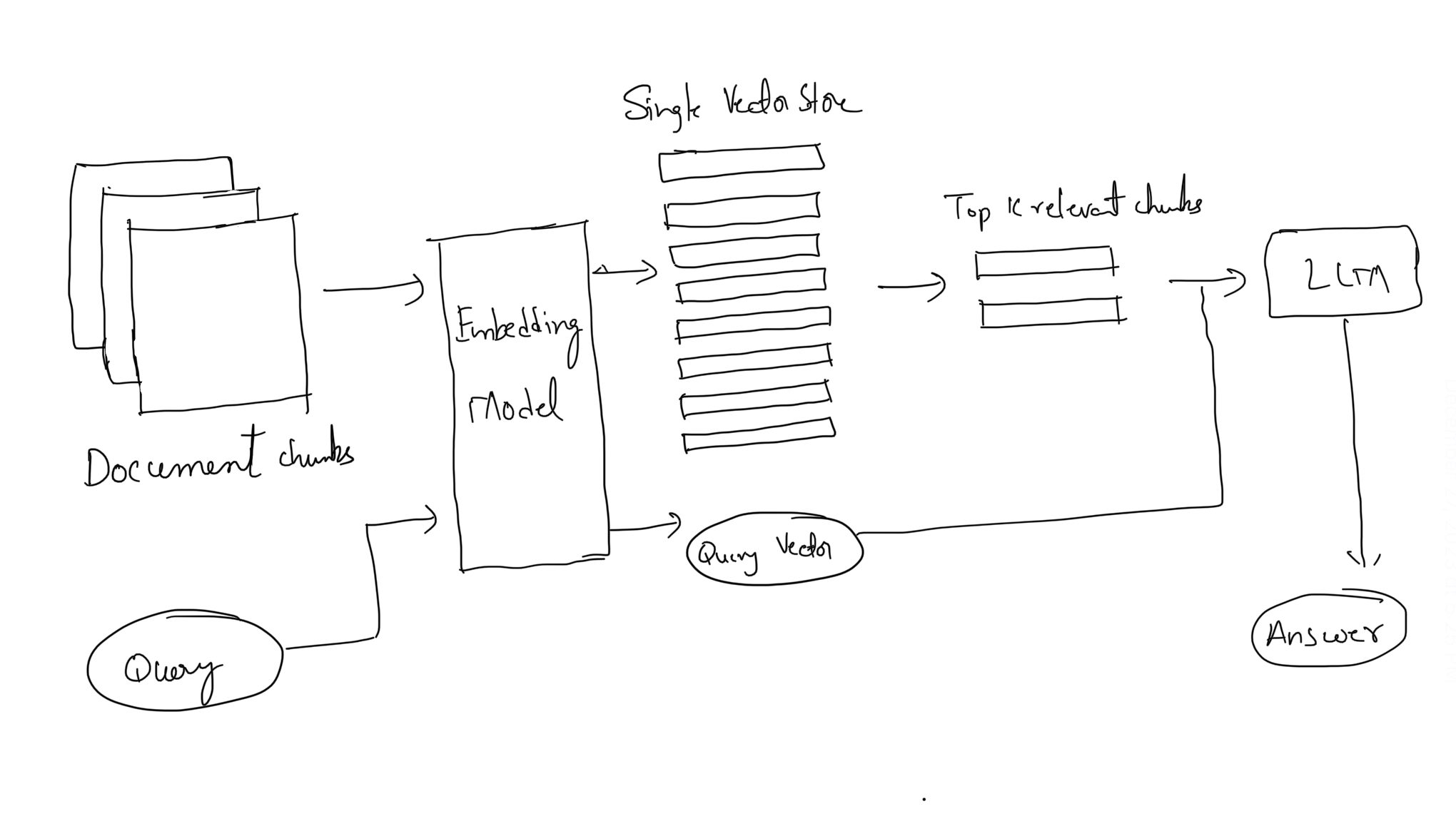
The heart of RAG is the search index, where content is stored in vectorized form. The simplest form is a flat index, leveraging metrics like cosine similarity to measure the likeness between query vectors and content vectors. This method is highly popular for its straightforward approach to determining similarity.
Cosine similarity measures the cosine of the angle between two vectors in a multi-dimensional space. It essentially assesses how similar the directions of two vectors are. The value ranges from -1 to 1, where 1 means exactly the same direction (highly similar), 0 indicates orthogonality (no similarity), and -1 indicates completely opposite directions. We calculate similarity scores between user vector query and with each vector chunk and then extract top-k similar chunks.
1.2 Hierarchical Indices
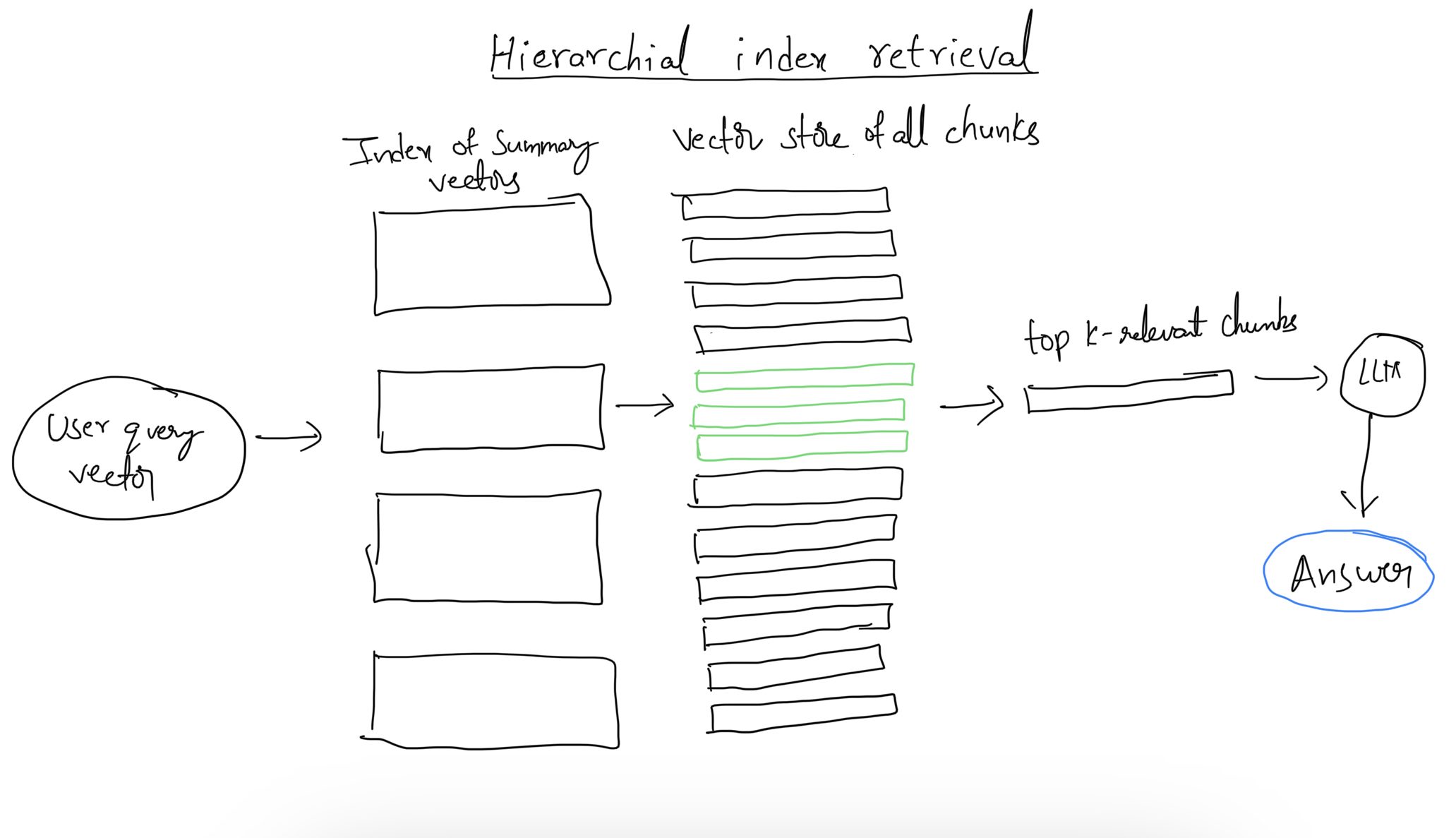
For larger document sets, a two-step approach is effective. Create one index for summaries and another for document chunks. This method allows for rapid filtering of relevant documents through summaries before diving into detailed searches within selected documents.
1.3 Hypothetical Questions and HyDE
The proposed method involves an LLM (Large Language Model) generating specific questions for each text chunk, which are then converted into vector form. During a search, queries are matched against this index of question vectors instead of the traditional chunk vectors. This enhances search quality, as the semantic similarity between the query and the hypothetical question tends to be higher than with a regular text chunk.
Furthermore, an alternative approach, dubbed HyDE (Hypothetical Direct Embedding), reverses this logic. Here, the LLM generates a hypothetical response based on the query. The vector of this response, combined with the query vector, is used to refine and improve the search process, ensuring more relevant and accurate results.
1.4 Small to Big Retrieval
This technique involves linking smaller data chunks to their larger parent chunks. When a relevant smaller chunk is identified, the corresponding larger chunk is retrieved, providing a broader context for the Large Language Model (LLM). This method includes the ‘Parent Document Retriever’ and ‘Sentence Window Retrieval,’ each focusing on expanding the context for more grounded responses.
1.4.1 Parent Document Retriever
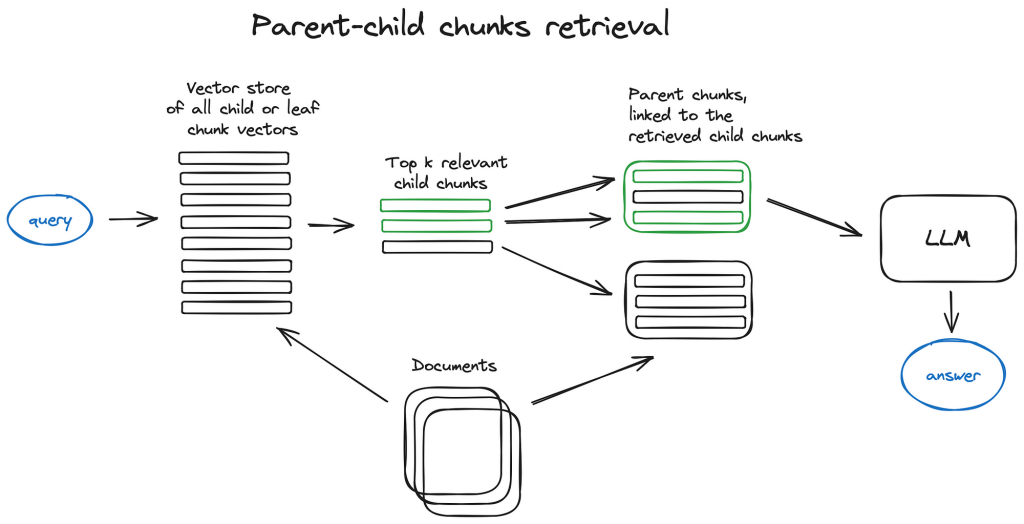
Begin by retrieving smaller segments of data that are most relevant to answering a query, then use their associated parent identifiers to access and return the larger parent chunk of data that will be passed as context to the LLM (Large Language Model).
1.4.2 Sentence window retrieval
Sentence Window Retrieval involves initially retrieving a specific sentence that is most relevant to answering a query and then returning a broader section of text that surrounds this sentence to give the LLM a much wider context to ground its responses. This is the same as Parent Document Retriever just that instead of chunks of text it is sentence chunks and expansion is a window above and below the sentence.

1.5 Fusion Retrieval
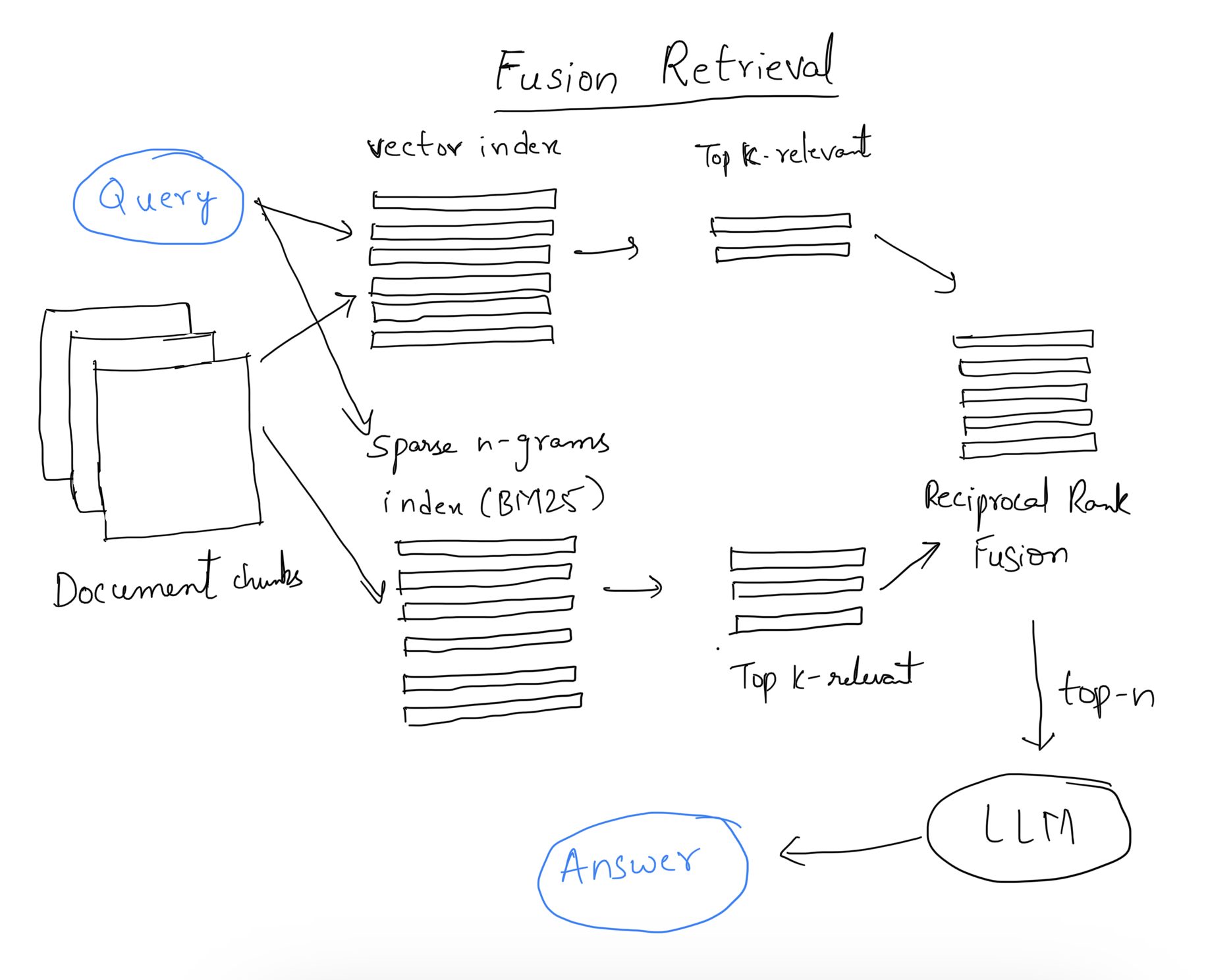
This approach combines traditional keyword-based search methods (like tf-idf or BM25) with modern semantic searches. The key here is integrating different retrieval results using algorithms like Reciprocal Rank Fusion for a more comprehensive output.
2. Reranking and Filtering
Post-retrieval, results undergo refinement through methods like filtering and re-ranking. Using tools like LlamaIndex’s Postprocessors, you can filter based on similarity scores, keywords, metadata, or re-rank using models like LLMs, sentence-transformer cross-encoders, or Cohere’s reranking endpoint.
3. Query Transformation
LLMs can be utilized to modify user queries for improved retrieval. This includes decomposing complex queries into simpler sub-queries or employing techniques like step-back prompting and query re-writing for enhanced context retrieval.
- Step-back prompting uses LLM to generate a more general query, retrieving for which we obtain a more general or high-level context useful to ground the answer to our original query.
Retrieval for the original query is also performed and both contexts are fed to the LLM on the final answer generation step. - Query re-writing uses LLM to reformulate the initial query to improve retrieval
4. Query Routing
Query routing is the decision-making step, determining the next course of action based on the user query. This could mean summarizing, searching a data index, or experimenting with different routes for a synthesized response. It also involves selecting the appropriate index or data store for the query using LLMs.
Conclusion
While there are other methods like reference citations and chat engines, the focus here is on those most applicable to production scenarios. Although some, like Agent RAG, offer intriguing possibilities, they may not yet be suitable for production environments due to their slower processing and higher costs.
Retrieval methods in RAG are dynamic and continually evolving. By understanding and applying these strategies, one can significantly enhance the capability of LLMs, leading to more accurate, relevant, and context-rich responses.
In the next part of this series, we see the end-to-end implementation of the RAG module using Llamaindex and Supabase as our vector database.









